Misrepresent data through visualizations of data
Misrepresenting Data
There are many ways to misrepresent data through visualizations of data. There are a variety of websites that exist solely to put these types of graphics on display, to discredit otherwise somewhat credible sources. Leo (2019), an employee of The Economist, wrote an article about the mistakes found within the magazine she works for. Misrepresentations were the topic of Sosulski (2016) in her blog. This is discussed in the course textbook, as well (Kirk, 2016, p. 305).
After reading through these references use the data attached to this forum to create two visualizations in R depicting the same information. In one, create a subtle misrepresentation of the data. In the other remove the misrepresentation. Add static images of the two visualizations to your post. Provide your interpretations of each visualization along with the programming code you used to create the plots. Do not attach anything to the forum: insert images as shown and enter the programming code in your post.
This is the data to use for this post: Country_Data.csv
Before plotting, you must subset, group, or summarize this data into a much smaller set of points. Include your programming code for all programming work.
References
Kirk, A. (2016). Data visualisation: A handbook for data driven design. Sage.
Leo, S. (2019, May 27). Mistakes, we've drawn a few: Learning from our errors in data visualization. The Economist. https://medium.economist.com/mistakes-weve-drawn-a-few-8cdd8a42d368
Sosulski, K. (2016, January). Top 5 visualization errors [Blog]. http://www.kristensosulski.com/2016/01/top-5-data-visualization-errors/
Considerations for every forum:
Remember your initial post on the main topic must be posted by Wednesday 11:59 PM (EST). Your 2 following posts, discussing and interacting peers' posts must be completed by Sunday at 11:59 PM (EST).
Your initial post should include your references, thoroughly present your ideas, and provide evidence to support those ideas. A quality peer response post is more than stating, “I agree with you.” State why you agree with your classmate’s post. Use the purpose of the forum is generate discussion.
No credit will be earned for posts that are disrespectful or not on the topic of the forum.
An example post:
The factual and misrepresented plots in this post are under the context that the visualizations represent the strength of the economy in five Asian countries: Japan, Israel, and Singapore, South Korea, and Oman. The gross domestic product is the amount of product throughput. GDP per capita is the manner in which the health of the economy can be represented.
The visual is provided to access the following research question:
How does the health of the economy between five Asian countries: Japan, Israel, and Singapore, South Korea, and Oman, compare from 1952 to 2011?
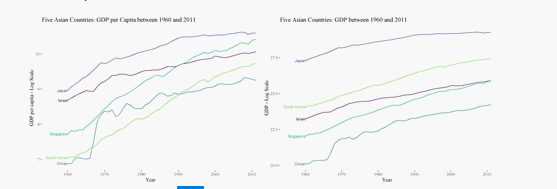
The plot on the left is the true representation of the economic health over the years of the presented countries. Japan consistently has seen the best economic health of the depicted countries. Singapore and South Korea both have large increases over the years, accelerating faster than the other countries in economic health. Oman saw significant growth in the years between 1960 and 1970, but the growth tapered off. All of the countries saw an increase in health over the provided time frame, per this dataset. Israel saw growth, but not as much as the other countries.
The plot on the right is only GDP and does not actually represent the economic health. Without acknowledging the number of persons the GDP represents, Japan is still the leading country over the time frame and within the scope of this dataset. Singapore's metrics depict some of the larger issues of representing the GDP without considering the population. Instead of Singapore's metrics depicting significant growth and having a level of health competitive with Japan in the true representation, Singapore has the fourth smallest GDP. It indicates that Singapore's economy is one of the least healthy amongst the five countries.
The programming used in R to subset, create, and save the plots:
# make two plots of the same information - one misrepresenting the data and one that does not
# use Country_Data.csv data
# plots based on the assumption the information is provided to represent the health of the countries' economy compared to other countries
# August 2020
# Dr. McClure
library(tidyverse)
library(funModeling)
library(ggthemes)
# collect the data file
pData <- read.csv("C:/Users/fraup/Google Drive/UCumberlands/ITS 530/Code/_data/Country_Data.csv")
# check the general health of the data
df_status(pData)
# no NA's no zeros
# look at the data structure
glimpse(pData) # nothing of note
# arbitrarily selected Asia, then list the countries by the highest gdp per capita, to plot competing economies*
# select countries - also use countries that cover all of the years in the dataset (52 years)
(selCountries <- pdata %>%
filter(continent == "Asia") %>%
group_by(country) %>%
summarise(ct = n(),
gdpPop = mean(gross_domestic_product/population)) %>%
arrange(-ct,
-gdpPop) %>%
select(country) %>%
unlist())
# many countries have 52 years worth of data
# good plot representation of the GDP per capita
p1 <- pdata %>%
filter(country %in% selCountries[1:5]) %>% # use subset to identify the top 5 countries to filter for
ggplot(aes(x = year, # plot the countries for each year
y = log(gross_domestic_product/population), # calculating the log of gdp/pop = GDP per capita
color = country)) + # color by country
geom_line() + # creating a line plot
scale_x_continuous(expand = expansion(add = c(7,1)), # expand the x axis, so the name labels of the country are on the plot
name = "Year") + # capitalize the x label, so the annotation is consistent
geom_text(inherit.aes = F, # don't use the aes established in ggplot
data = filter(pData, # filter for one data point per country for the label, so one label per country
country %in% selCountries[1:5],
year == 1960),
aes(label = country, # assign the label
x = year,
y = log(gross_domestic_product/population), # keep the axes and color the same
color = country),
hjust = "outward", # shift the text outward
size = 3) + # make the text size smaller
scale_color_viridis_d(end = .8, # don't include the light yellow, not very visible
guide = "none") + # no legend, because of text labels
scale_y_continuous(name = "GDP per capita - Log Scale") + # rename y axis
ggtitle("Five Asian Countries: GDP per Capita between 1960 and 2011") + # plot title
theme_tufte()
# misrepresent economic health - don't account for population
p2 <- pdata %>%
filter(country %in% selCountries[1:5]) %>% # use subset to identify the top 5 countries to filter for
ggplot(aes(x = year, # plot the countries for each year
y = log(gross_domestic_product), # calculating the log of gdp
color = country)) + # color by country
geom_line() + # creating a line plot
scale_x_continuous(expand = expansion(add = c(7,1)), # expand the x axis, so the name labels of the country are on the plot
name = "Year") + # capitalize the x label, so the annotation is consistent
geom_text(inherit.aes = F, # don't use the aes established in ggplot
data = filter(pData, # filter for one data point per country for the label, so one label per country
country %in% selCountries[1:5],
year == 1960),
aes(label = country, # assign the label
x = year,
y = log(gross_domestic_product), # keep the axes and color the same
color = country),
hjust = "outward", # shift the text outward
size = 3) + # make the text size smaller
scale_color_viridis_d(end = .8, # don't include the light yellow, not very visible
guide = "none") + # no legend, because of text labels
scale_y_continuous(name = "GDP - Log Scale") + # rename y axis
ggtitle("Five Asian Countries: GDP between 1960 and 2011") + # plot title
theme_tufte()
# save each plot with a transparent background in the archive image folder
ggsave(filename = "PerCapita.png",
plot = p1,
bg = "transparent",
path = "./code archive/_images")
ggsave(filename = "GDP.png",
plot = p2,



