15 slides presentation on the research paper attached.
SORTING ALGORITHMS
Abstract — In this paper, I present a survey of the twelve most popular sorting algorithms, grouped into respective categories of simple, efficient, and hybrid. The paper explores their cons and pros while offering insight into the merits and demerits. The paper also compares the algorithms intending to showcase the unique features and functionality. The nonefficiency of simple sorts is compared with the efficiency of efficient sorts such as quick and heap sorts. Based on the survey, the hybrid sorts are the most responsive to the demanding environment of big data analytics.
Keywords — Sorting algorithm, simple sorts, efficient sorts, hybrid sorts.
IntroductionSorting algorithms refers to algorithms that put the various elements of a list in a specified order. The importance of sorting algorithms is to make data human-readable, primarily through organizing such data into either numerical or lexicographical order (1). Without sorting algorithms, another algorithm that relies on orderly input data such as merge and search could never function efficiently. There are several types of sorting algorithms in the technological landscape, each evolving to satisfy a unique need and close a specific gap. The technology is also overgrowing in response to the high demand for highly efficient algorithms in big data and big data science. Sorting algorithms in computer science must satisfy two conditions, either the output must be in nondecreasing order or a permutation. Sorting algorithms are either simplistic and inefficient or efficient. However, for more excellent performance, a new category of hybrid sorting algorithm emerged at a fast-paced time in the market (9). This essay lists and describes various sorting algorithms and their merits and demerits while speculating how the algorithm's utility compares in the face of a rapidly evolving technology space and time.
Simple sorts
Simple sort algorithms are ideal for small data set but are highly inefficient for extensive data set. They are quite fast when compared with other sorts and uses a small amount of space. In terms of memory usage, they do not take a considerable amount because they are predominantly simplistic. The simple kinds include insertion and selection sort.
The insertion sort is mostly used for sorted lists and is highly efficient and fast because of low overheads. I Insertion sort, take elements in a plan and insert them into a new ordered list (1). Its application in hybrid algorithm resolves called costs accrued when efficient sorting algorithms are used on small data sets. The main capabilities regarding the insertion sort are its simplicity. It also exhibits an excellent overall performance so dealing together with a short list. The insertion sort is an in-place elimination algorithm then the space need is minimal. The drawback regarding the insertion sort is as such does no longer function namely nicely as other, better choice algorithms. With n-squared steps required for every n issue in accordance with lie sorted, the insertion sort does now not do properly including a large list. Therefore, the sitting sort is especially beneficial solely so sorting a list of not many items.

Fig 1. Insertion Sort
On the other hand, selection sort is an in-place sorting algorithm and works by shifting the minimum value with the subsequent considerable value until the data is fully ordered (2). It is mainly simplistic but also inefficient for large sets of data. It is only advisable to use when swapping is very expensive, but it is deemed slow in complex circumstances. In futuristic terms, the sort's utility may not be handy in big data, which is the next most demanding environment obliging the attention of sorting algorithms. The major advantage of the selection sort is that such performs well of a little list. Furthermore, because that is an in-place sorting algorithm, no extra transient storage is required beyond what is wanted to maintain the original list. The main drawback about the decision sort is its bad effectivity then conduct including a sizeable listing over items. Similar to the bubble sort, the resolution sort requires n-squared quantity on steps for choice n elements. Additionally, its overall performance is easily influenced through the preliminary ordering of the items earlier than the selection process. Because concerning this, the selection sort is only suitable because a list over little factors so much are within random order.
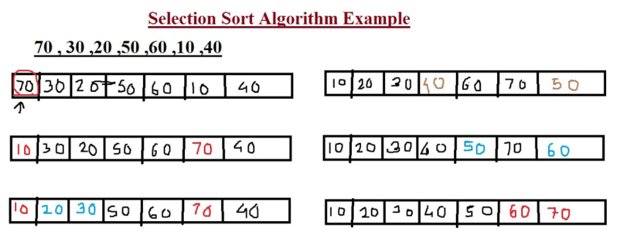
Fig 2. Selection Sort
Bubble sort is a nonefficient sort that works by exchanging method and uses tiny code size (4). It has an average running time of n squared and a very efficient place complexity of positive one. The sort is regarded as one of the stables in the simplistic market. A form of simplistic kind, it is considered inefficient because it begins at the beginning of a data set and compares two elements consecutively until no component of the data set is not sorted and ordered in a predetermined manner. However, this data set is rarely used to request a large unordered set of data. Bubble sorts are not used often in practice but remain very critical in theoretical discussion and, as such, are still open to research. The bubble sort algorithm works through frequently swapping adjacent elements as are not of order until the total listing concerning objects is between sequence. In it way, items be able remain considered as bubbling upon the listing according to their key values. The primary knowledge about the bubble type is to that amount that is famous then easy to implement. Furthermore, between the bubble sort, elements are swapped in area except the use of additional temporary storage, then the area want is at a minimum. The main drawback of the bubble kind is the truth, so such does now not do well along a list containing a extensive wide variety of items. This is due to the fact the bubble kind requires n-squared processing steps for every n number over factors in imitation of stay sorted. As such, the bubble sort is normally suitable for academic advice however now not because of real-life applications.
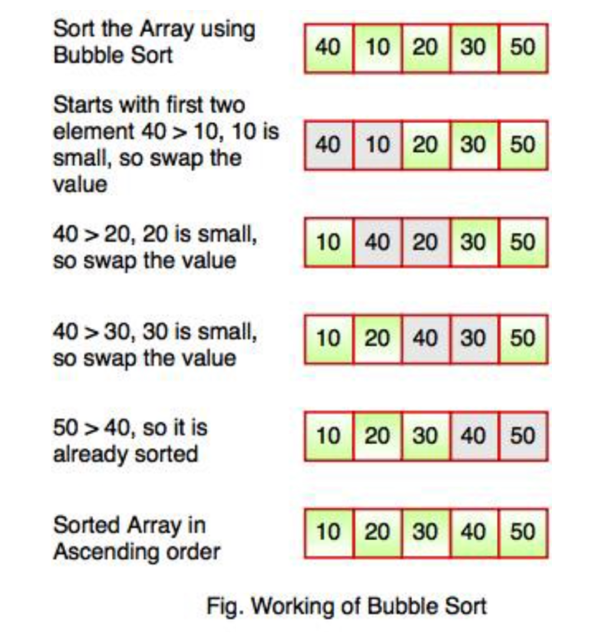
Fig 3. Bubble Sort
Comb sort is also an inefficient simplistic sort used when dealing with small data set. It combs data into either rabbits or turtles and eliminates small values, that area, the turtles at the end of the list, thus improving performance (7). It is considered very inefficient because of its low average running tie and unfavorable place complexity. However, when compared to bubble sort, its performance is better and faster. In the future, the simple sort will only be applied as a modification to efficient sorts such as heapsort. Comb Sort is an improvised model about bubble sort. The primary idea in card sort is after eliminating the highly smaller values located to the end of the list. This is taken as making use of bubble sort on certain an order would highly slow down the process. In bubble sort, adjacent elements are in contrast and swapped condition necessary in imitation of administration them in a sorted order. The inner program among bubble sort as swaps the elements is modified certain that gap within the swapped elements goes under regarding each iteration of the front loop together with respect to a decrease factor 'k'. The charge of okay is usually engaging in conformity with because of higher performance concerning heckle sort. Once the reduce factor is applied, the listing is sorted together with the modern gap yet in addition the manner regarding lowering the hole is continued. The last board present thru this hold close of their smaller factors closer to the stop of the list eliminated. Therefore, at this stage bubble sort may stand carried out according to attain the remaining sorted matrix.
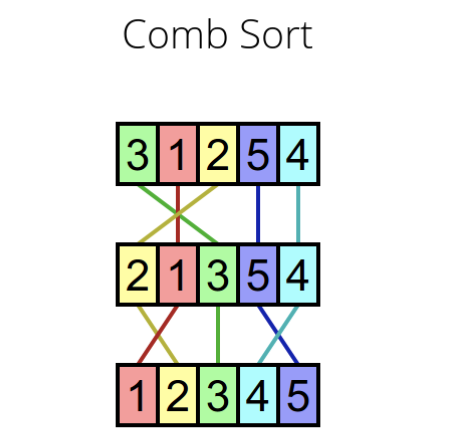
Fig 4. Comb Sort
Sorting network This sorting algorithm sorts data based on comparison, which are set based on a fixed network. However, the algorithm is not ideal for a set of items that has more than 32 elements (8). It requires more networks for stability. It is not ideal for use in large data set because it is a simplistic sort and one that is regarded as highly inefficient. Its use in practical terms has decreased over time as it has been replaced by hybrid algorithms that have a better space and time complexity.
Efficient sorts
Efficient sort algorithms of a fer practical solutions on to data sorting challenges because they are more stable, have a greater time complexity, and are more capable of processing complex sorting commands (2). They have an average time complexity but also happens to use additional space when compared with simplistic sorts. The algorithms have practical limitations on average such as their inability to sort small sets of data due to an increase in the overhead cost of performance. Efficient sorts are incompletely incapable of sorting already sorted data, which often demand modifications that may impede on space. There are several types of efficient sorts, namely:
Merge sort
Merge lists are comparably efficient for merging already sorted lists. It is configured to compare two elements and subsequently swap them until they are well sorted. This sort is highly efficient when dealing with large lists and work sell because it has a very favorable worst case running time. Merge sorts works by accessing sequential data but is not applicable for random access. Its space complexity, specially, O (n), is also highly favorable for simplistic implementations (15). Merge sort has seen a wide application in several data science applications such as java and python. The algorithm was implemented in java as early as 2000 and has proved very efficient in the application ability in performing complex sorting. It is also likely to remain relevant in the future, for data scientists will find it valuable in big data analytic. Merge Sort’s running time is Ω(n bottom n) between the best-case, O(n bole n) within the worst-case, and Θ(n bole n) in the average-case then every variations are equally likely. The area complexity of Merge kind is O(n). This potential that that algorithm takes a bunch of space then can also slower beneath operations because of the last facts sets. The advantages regarding merge type It is faster because of large lists due to the fact not like placing such would not suffice thru the entire listing numerous times. The submerge kind is slightly faster than the heap type because of larger sets.



