Project Deliverable 4
Running head: DATABASE AND PROGRAMMING DESIGN
Project Deliverable 3: Database and Programming Design
CIS498
May 14, 2017
Introduction
Data growth is an expected aspect for any organization with extensive information technology operations. As many organizations become alive to the importance of their data and the insights they could get from it, they are turning to expert solutions. Identifying the right solution is the difference success and failure. As such, it is very vital that the organizations take the time to carefully assess their options and make appropriate decisions in that regard.
Knight Inc would like to grow its business to cover more markets and sell more products. Its technological implementations will play a big part in the successful achievement of this. Data processing has become a centrally important aspect of the infusion of technology into businesses. For an organization like Knight, data is produced in large amounts as a result of their business operations. Making sense of this data is important for them because of the benefits it would portend for the business. An effective data processing apparatus needs to make sense of all the data the company generates and provide insights into how the how can take advantage of it.
Decision making is a very important part of any organization’s operations. Senior management has to make a myriad of decisions everyday on a variety of issues. Sound decisions are those that are based off of sound facts. These facts are provided by the analysis of data generated within the company. Once the senior management officials have been provided with information on the status of their organizations, they can make decisions that are directly influenced by the information. It is therefore very important that the information provided to them is unimpeachable. It has to stand the integrity test and be trusted given their implications on the health of the business. Executive oversight is an important part of an organization. Executives having set out goals and performance objectives for their companies, need to know that these are been met. They need to conduct evaluations on the progress of their organizations and get to understand them. With data processing and analysis, this is made quite accessible. They are able to request information on the company and receive it in real time. Once they have this ready access to data, it becomes easier to guide the direction of their organizations and shape them in ways that they want to. (Umanath, & Scamell, 2014).
Relational databases are some of the approaches that organizations can implement to get a better grip of their data assets. These databases are easy to create given that they mainly use tables to store and manage data. Separate tables for separate classes of data can be created whenever they are required. This ability to separate data makes it fairly easy to secure data given how data with differing security classifications can be placed in different tables. Relational databases can be extended to cater for more data and this is possible without actually requiring any modifications to be made to the applications that depend on the database.
Data warehousing is another very important way of implementing a sound data processing and analysis strategy. A data warehouse is essentially a repository of data collected from a variety of sources. Data warehouses are usually created in response to existing data and how it can be managed. A data warehouse is created from an agglomeration of data marts which are repositories for data aimed at a specific group of people. Many data marts can be collected to form a data warehouse in what is known as the bottom-up approach or they can be spun off from the data warehouse in what is known as the top-down approach. Since most organizations are already maintaining data marts for their various internal departments, the bottom-up is usually the more used of these two approaches. The data warehouse will be integrated, nonvolatile and time variant. (Vaisman, & Zimányi, 2014).
A data warehouse and relational database can be hosted on a company’s internal mainframe or as more organizations are doing today, it could be stored in the cloud. The latter option apart from being way cheaper is also greatly flexible and easily accessible from multiple areas. Knight has an e-commerce platform as its primary operation and as such online transaction processing is a big part of what it does. The analytical applications deployed can be then pick out then pick out the data from these transaction processing and use it make analysis of the system and present the organization with actionable insights. (Vaisman, & Zimányi, 2014).
Organizations that use the above tools will spend fewer resources on supervision of their visions and also their employees given how accessible it will be. It will take shorter times to make decisions as it will be much easier to get access to vital information about the company.
Database Schema
A database schema is a skeletal representation of the logical view of a database. It presents the relationships and associations that can be made with the data presented in it. Below is a database schema for Knight Inc.’s database.
Figure 1: Database schema
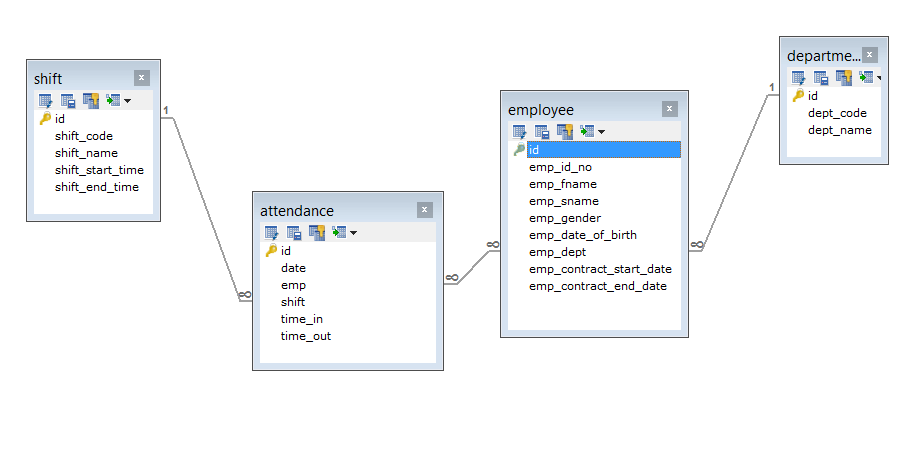
Relational databases will be used for implementing Knight’s data strategy. They will be used to provide easy querying of the system and provide a streamlined system that is devoid of redundancy. (Umanath, & Scamell, 2014). Relational databases given their extensibility can also be used to implement the data warehouse strategy for Knight Inc.
Rationale
The rationale for the above schema which is the employee’s information module is that it is a much easier approach. The above schema has multiple tables like employee details and their departments. With this clear demarcation, it becomes much easier to track this information under this arrangement. Within each table is a primary key which is a unique identifier for the particular table. It is also that much easier to report with this arrangement. With the above schema, each employee will be given a unique key to differentiate them. With this key, they will be represented across different table. Should changes to an employee’s information be made, the primary key will ensure that updates are made in all tables where the updated information is important. Employee contract details, shift details and such will be among the aspects that might change during the course of their employment.
Database Tables and Referential Integrity
Figure 2: Database Tables

M 1 1 M
Un-Normalized Form (UNF)
Un-normalized forms have the database tables with non-atomic values on every row. Atomic values are those that cannot be decomposed any further while non-atomic values can be decomposed. Instances of the same data cannot be repeated on more than one table in un-normalized form. (McGwin, 2014).
First Normal Form (1NF)
In a first normal form, a column of a table cannot hold multiple values, only atomic values. Repeating information groups can also not be in two rows. On every table are rows and each row has a unique primary key to set apart from the rest. While a single column can be used as a primary key, more columns can be combined to form one primary key. (McGwin, 2014).
Second Normal Form (2NF)
A table qualifies to be termed as second normal form if it fulfills two conditions. It must first be in first normal form and there is no dependency of a non-prime attribute on a candidate key. Attributes not part of a candidate are referred to as non-prime attributes. Tables with concatenated primary keys will have columns dependent on the concatenated key if the column is not part of the primary key. Should even a single column be found to be dependent on the concatenated key, then it fails to be qualified as second normal form. (McGwin, 2014).
Third Normal Form (3NF)
A table must have all of its non-prime attributes dependent on the primary key to qualify as third normal form. Non-prime attributes can also only be determined by other non-prime attributes. Attributes and data have to be fully dependent on the primary key or be removed if they don’t. There must be transitive functional dependency on a table and it must also be in second normal form. Removing transitive functional dependency reduces the amount of data duplication and leads to the achievement of data integrity (McGwin, 2014).
Referential integrity will be implemented to ensure that there are no conflicts with the records of the database. Updates made in one table will be simultaneously reflected in other tables where the data is used to. This is to ensure that all transactions being carried out on a particular piece of entity is using consistent data across all areas the transactions are being carried out. Essentially, with referential integrity, all data will be consistent as updates will be automatic.
For a table to be normalized to third form, it needs to be a second normal form devoid of transitive dependency. Should any table within the database have transitive dependency, this disqualifies the table from being normalized into the 3NF. For redundancy purposes, in third normal form, any data that is not fully dependent on the primary key. To ensure that data is not lost during updates, there should be no row in a table with referencing column as a non-null value if there is also no equal value in the reference column. (Coronel, & Morris, 2016).
Entity Relationship Diagram
Figure 2: The Entity Relationship Diagram
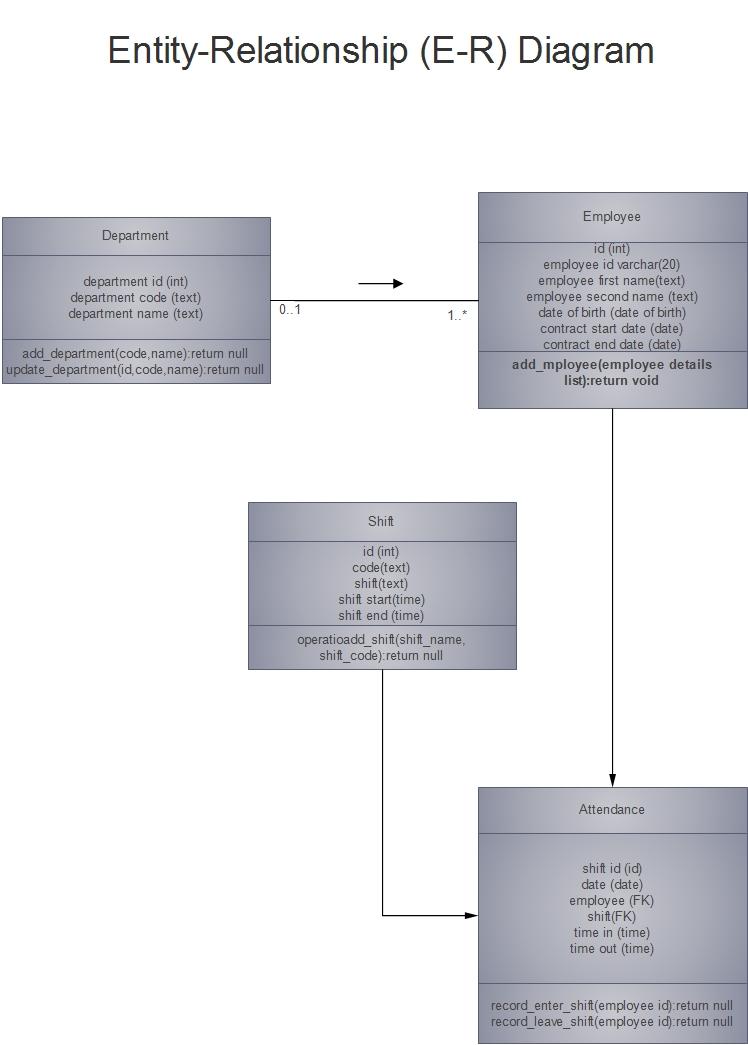
Rationale
There will be four objects interacting in the database. With the department table, it will inherit from the employees table object and they will have a one to many relationship. There will several instances of a department in the employee table. With the attendance table, it will inherit from both the shift and employee table and will have a one to many relationships with each other. The shift table will require a daily update given its nature.
Dataflow Diagram
Figure 3: The dataflow diagram
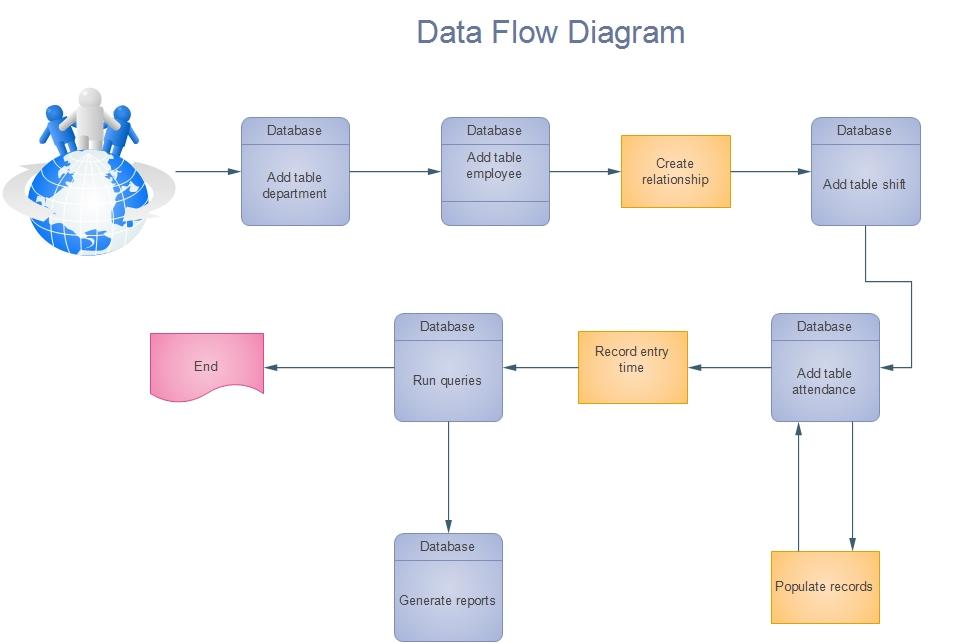
Rationale
Above is a representation of the setup process of the system with the various important tables that will be involved. From the main departmental records, they will be set up first and then followed by employees’ tables and the many relationships it will have. They will then be followed by shifts and attendance. Reports can then be generated as requested.
Sample Queries
Sample Queries are as follows:
SELECT * FROM employee
Displays all the employees of the company
SELECT employee.emp_fname, employee.emp_sname, attendance.date, attendance.shift, attendance.time_in, attendance.time_out
FROM attendance
LEFT JOIN employee
ON attendance.emp = employee.id
Displays all employee attendance records
Screenshots
Figure 4: Employee Edit Screen
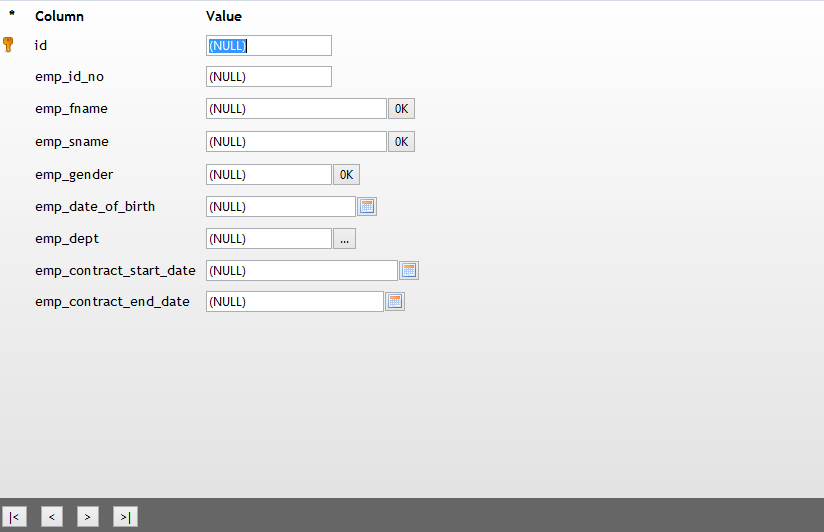
Figure 5: Shift Record Screen
Conclusion
It has become evident that any organization can implement a successful data processing and analysis operation if they adhere to the central tenets. They should tailor their solutions to their own situations and have specific implementations that work for them. Experts should be involved throughout the process to ensure that all important features are covered. They should also pay attention to matters of information security and implement them accordingly.
References
Umanath, N. S., & Scamell, R. W. (2014). Data modeling and database design. Nelson Education.
Vaisman, A., & Zimányi, E. (2014). Data Warehouse Systems. Springer, Heidelberg.
Coronel, C., & Morris, S. (2016). Database systems: design, implementation, & management. Cengage Learning.



