scenario
Chapter 9 Notes Designing Databases
File and database design occurs in two steps.
Develop logical database model, describes data using notation
Relational database model
Technical specification for computer files and databases in which to store the data, this results in a physical database provides the specifications
Logical and physical design in parallel with other system design steps
Four Steps in logical database modeling and design
Develop a logical data model for each known user interface for the application using normalization principles.
Combine normalized data requirements from all user interfaces into one consolidated logical database model (view integration).
Translate the conceptual E-R data model for the application into normalized data requirements.
Compare the consolidated logical database design with the translated E-R model and produce one final logical database model for the application.
Team then moves into the physical database design:
Choosing a storage format for each attribute from the logical database model.
Grouping attributes from the logical database model into physical records.
Arranging related records in secondary memory (hard disks and magnetic tapes) so that records can be stored, retrieved and updated rapidly.
Selecting media and structures for storing data to make access more efficient.
Logical database design: Must account for every data element on a system input or output, Normalized relations are the primary deliverable.
Physical database design: Converts relations into database tables, Programmers and database analysts code the definitions of the database. Written in Structured Query Language (SQL)
Figure 9-3
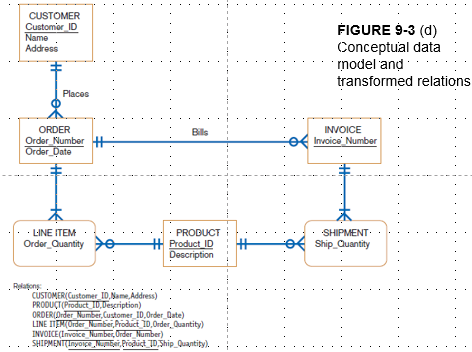
Relational Database Model: data represented as a set of related tables or relations
Relation: named, two-dimensional table of data; each relation consists of a set of named columns and an arbitrary number of unnamed rows
Relations have several properties that distinguish them from nonrelational tables
Entries in cells are simple.
Entries in columns are from the same set of values.
Each row is unique.
The sequence of columns can be interchanged without changing the meaning or use of the relation.
The rows may be interchanged or stored in any sequence.
Well Structured Relation (or table)
a relation that contains a minimum amount of redundancy
allows users to insert, modify, and delete the rows without errors or inconsistencies
Primary key – attribute (or combination of attributes) whose value is unique across all occurrence of a relational
All relations have a primary key
this is how rows are ensured to be unique
primary key may involve a single attribute or be composed of multiple attributes
Normalization – the process of converting complex data structures into simple, stable structures
overriding goal is minimizing unnecessary redundancy and maximizing integrity (correctness)
the result of normalization is that every non-primary key attribute depends upon the whole primary key
First Normal Form (1NF): unique rows, no multivalued attributes, all relations are 1NF (precondition for qualifying for second normal form)
Second Normal Form (2NF): each non-primary key attribute is identified by the whole key(called full functional dependency)
Third Normal Form (3NF): non primary key attributes do not depend on each other (i.e., no transitive dependencies)
Functional dependency a particular relationship between two attributes
For a given relation, attribute B is functionally dependent on attribute A if, for every valid value of A, that value of A uniquely determines the value of B.
Example: Table of records for employees. Uniquely identify each employee by Employee ID. Last name is deptermined by Employee ID. Last name is functionally dependent on primary key.
The functional dependence of B on A is represented by A→B.
Figure 9-9
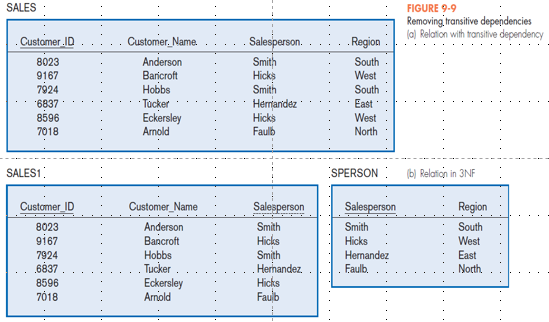
Foreign Key – attribute appears as a non-primary key attribute in one relation and as a primary key attribute (or part of a primary key) in another relation
Referential Integrity – integrity constraint specifying that the value (or existence) of an attribute in one relation depends on the value (or existence) of the same attribute in another relation
Transforming E-R diagrams into relations
1)Represent entities
2)Represent relationships
3)Normalize the relations
4)merge the relations
Primary key must satisfy the following two conditions:
1) value of the key must uniquely identify every row in the relation
2) the key should be non-redundant
Figure 9-11
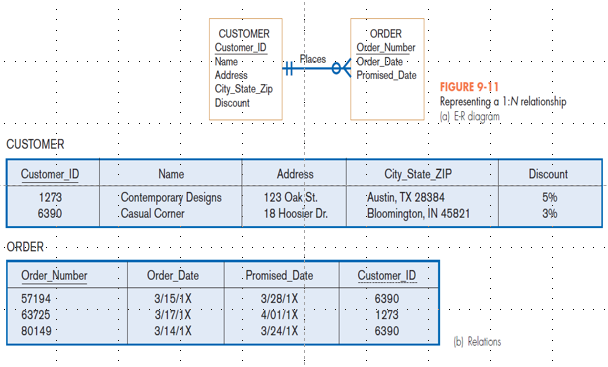
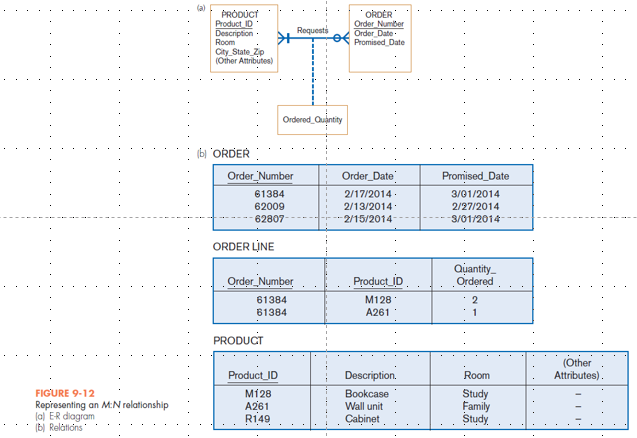
Figure 9-12 Many to Many Relationship
Merging Relations-
Physical File and Database Design
The following information is required:
Normalized relations, including volume estimates
Definitions of each attribute
Descriptions of where and when data are used, entered, retrieved, deleted, and updated (including frequencies)
Expectations or requirements for response time and data integrity
Descriptions of the technologies used for implementing the files and database
Field: smallest unit of named application data recognized by system software
Data Type: coding scheme recognized by system software for representing organizational data
Selecting a data type balances four objectives:
Minimize storage space.
Represent all possible values of the field.
Improve data integrity of the field.
Support all data manipulations desired on the field.
Table 9-2

Calculated (or computed or derived) field: a field that can be derived from other database fields
It is common for an attribute to be mathematically related to other data.
The calculate value is either stored or computed when it is requested.
Controlling Data Integrity
Default Value: a value a field will assume unless an explicit value is entered for that field
Range Control: limits range of values that can be entered into field; Both numeric and alphanumeric data
Referential Integrity: an integrity constraint specifying that the value (or existence) of an attribute in one relation depends on the value (or existence) of the same attribute in another relation
Null Value: a special field value, distinct from zero, blank, or any other value, that indicates that the value for the field is missing or otherwise unknown
Designing Physical Tables
Relational database is a set of related tables.
Physical Table: a named set of rows and columns that specifies the fields in each row of the table
Denormalization: the process of splitting or combining normalized relations into physical tables based on affinity of use of rows and fields
Denormalization optimizes certain data processing activities at the expense of others.
Three types of table partitioning:
Range partitioning: partitions are defined by nonoverlapping ranges of values for a specified attribute
Hash partitioning: a table row is assigned to a partition by an algorithm and then maps the specified attribute value to a partition
Composite partitioning: combines range and hash partitioning by first segregating data by ranges on the designated attribute, and then within each of these partitions
Various forms of denormalization, which involves combining data from several normalized tables, can be done.
No hard-and-fast rules for deciding
Three common situations where denormalization may be used:
Two entities with a one-to-one relationship
A many-to-many relationship (associative entity) with nonkey attributes
Reference data
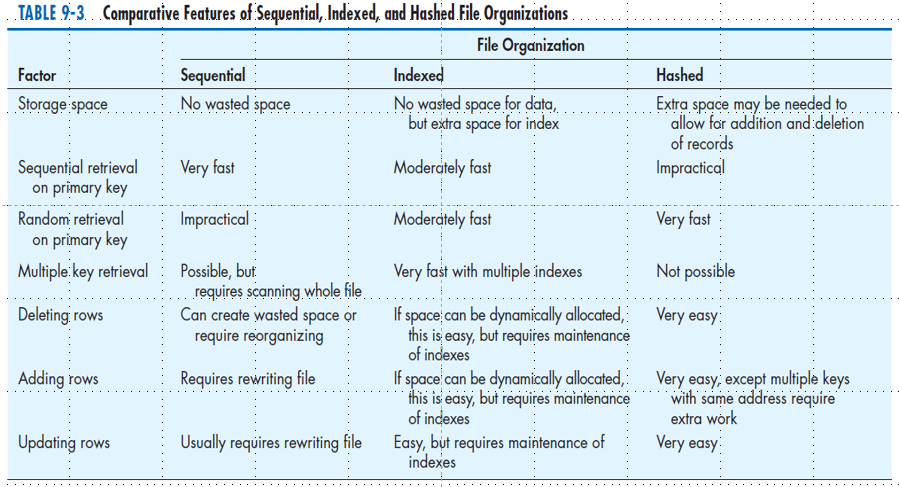
File organization: a technique for physically arranging the records of a file
Physical file: a named set of table rows stored in a contiguous section of secondary memory
Sequential file organization: a file organization in which rows in a file are stored in sequence according to a primary key value
Hashed file organization: a file organization in which the address for each row is determined using an algorithm
Pointer: a field of data that can be used to locate a related field or row of data
Table 9-3
Arranging Table Rows
Objectives for choosing file organization
Fast data retrieval
High throughput for processing transactions
Efficient use of storage space
Protection from failures or data loss
Minimizing need for reorganization
Accommodating growth
Security from unauthorized use
Indexed File Organization
Indexed file organization: a file organization in which rows are stored either sequentially or nonsequentially, and an index is created that allows software to locate individual rows
Index: a table used to determine the location of rows in a file that satisfy some condition
Secondary keys: one or a combination of fields for which more than one row may have the same combination of values
Indexed File Organization (Cont.)
Main disadvantages:
Extra space required to store the indexes
Extra time necessary to access and maintain indexes
Main advantage: Allows for both random and sequential processing
Guidelines for choosing indexes
Specify a unique index for the primary key of each table.
Specify an index for foreign keys.
Specify an index for nonkey fields that are referenced in qualification, sorting and grouping commands for the purpose of retrieving data.
Designing Controls for Files
Two of the goals of physical table design are protection from failure or data loss and security from unauthorized use.
These goals are achieved primarily by implementing controls on each file.
Two other important types of controls address file backup and security.
Techniques for file restoration include:
Periodically making a backup copy of a file.
Storing a copy of each change to a file in a transaction log or audit trail.
Storing a copy of each row before or after it is changed.
Means of building data security into a file include:
Coding, or encrypting, the data in the file.
Requiring data file users to identify themselves by entering user names and passwords.
Prohibiting users from directly manipulating any data in the file by forcing users to work with a copy (real or virtual).
Physical Database Design for Hoosier Burger
The following decisions need to be made:
Decide to create one or more fields for each attribute and determine a data type for each field.
For each field, decide if it is calculated; needs to be coded or compressed; must have a default value or picture; or must have range, referential integrity, or null value controls.
For each relation, decide if it should be denormalized to achieve desired processing efficiencies.
Choose a file organization for each physical file.
Select suitable controls for each file and the database.
Electronic Commerce Application: Designing Databases
Designing databases for Pine Valley Furniture’s WebStore
Review the conceptual model (E-R diagram).
Examine the lists of attributes for each entity.
Complete the database design.
Share all design information with project team to be turned into a working database during implementation.
Potential Questions
Explain the purpose of normalizing relational database designs
Differentiate the meanings of first, second, and third normal forms
What are the goals of ‘denormalizing’ a relational database to some degree?
Specify and explain the chronological order of the following processes: Physical Database Design, Conceptual Data Modeling, Logical Data Modeling
How is a relationship between two tables in a relational database actually formed?
Explain how a many-to-many relationship between two tables in a relational database is made possible



